Aegis Platform Overview
The Aegis stack is an enterprise-grade framework for building, deploying, and managing LLM-powered agents and retrieval systems. It is designed to help engineering teams move from fast prototyping to robust, secure, and observable AI workflows.
This document provides a high-level tour of the key components in the Aegis architecture and how they interact in production environments.
🔧 Core Design Principles
- Modular microservices: Each component is independent and replaceable.
- Structured agent interfaces: Agents use typed inputs/outputs and can call tools.
- Access-aware RAG: All retrieval honors document-level access control.
- Evaluation-native: Every agent run can be scored, compared, and traced.
- Orchestration-first: Data and agent workflows are both centrally orchestrated.
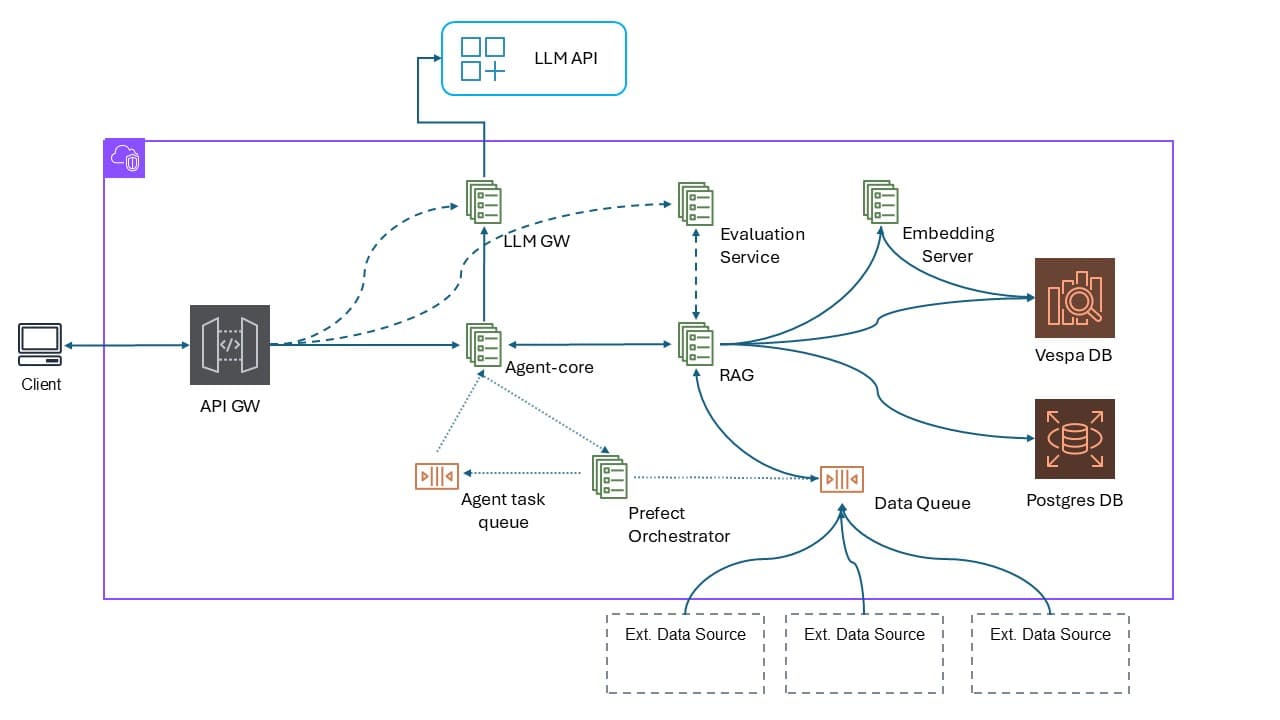
📦 Platform Components (by Architecture Layer)
1. API Gateway (API GW)
The entry point for all external clients.
- Authenticates requests (Auth0 or API Key)
- Injects tenant/user context
- Forwards calls to agent-core or other internal services
- Enforces RBAC and ABAC
2. Agent-Core
The runtime service for agent execution.
- Loads agent configs and structured schemas
- Runs tools, LLM calls, and team flows
- Interfaces with:
- LLM Gateway for completions
- RAG service for contextual grounding
- Evaluation Service for inline scoring
- Orchestrator for queue-triggered runs
3. LLM Gateway (LLM GW)
Manages access to external LLM providers.
- Supports OpenAI, Anthropic, Azure, etc.
- Tracks token usage, cost, and rate limits
- Supports stub replay and budget enforcement
4. RAG Service
Structured Retrieval-Augmented Generation pipeline.
- Handles chunking, indexing, and search
- Performs hybrid (vector + lexical) retrieval with Vespa
- Applies strict access filters during retrieval
- Semantic RAG: A key enhancement for enterprise grade workflows. Supports semantic tags generted by agents with links/metadata to other documents
5. Evaluation Service
Scoring and feedback pipeline for agent output.
- Real-time and batch evaluation support
- Built-in metrics (F1, accuracy, precision)
- Stores evaluator logs and run history
- Sends feedback to observability or retraining tools
6. Embedding Server
Internal microservice that handles all embedding operations.
- Embeds documents and chunks before indexing
- Sends vectors to Vespa
- Handles multi-model support if needed
7. Prefect Orchestrator
Manages asynchronous data and agent workflows.
a. Data pipeline:
- Pulls from external sources (S3, GCS, EMR)
- Extracts + cleans sections via Unstructured
- Triggers chunking → embedding → indexing
b. Agent pipeline:
- Triggers multi-agent graph flows from queue
- Stores results and run traces
- Enables scheduled or event-driven execution
8. Postgres DB
Transactional system-of-record for:
- Agent and team definitions
- Run logs and evaluation metadata
- Access control metadata
- Document and chunk metadata
9. Vespa DB
High-performance hybrid retrieval system.
- Stores document embeddings and metadata
- Supports vector + keyword + structured filters
- Ranks results based on customizable profiles
🔄 Data and Execution Flow (Overview)
- A client sends a request to the API GW.
- The API GW routes to
agent-corewith scoped context. - Agent-core runs tools, calls LLMs via
LLM GW, and retrieves context fromRAG. - If evaluation is enabled, output is scored and logged.
- Prefect flows handle background ingestion or scheduled agent runs.
- Vespa and Postgres store document context and metadata.
📈 Observability and Auditing
- TBC